学生时代写的博客,被我恢复了出来了……这篇文章应该大二写的,也就是2008年
Peter Norvig真乃神人!在坐飞机这么短的时间内就揣摩出了一个简单的拼写检查数学模型,我看后实在是佩服。他的模型很好地利用了贝叶斯(Bayes)理论描述了拼写检查的几个关键概率点,简单又易懂。我看后兴致勃勃,用C做了一个实现(代码附在文章的末尾)。为了使大家能够看懂我的代码,我下面给大家简单说明一下Peter Norvig的理论,如果你英语够好的话,可以访问 hutp://norvig.com/spell-correct.html来阅读原版。
首先就是一点简单的概率理论,设随机变量c是给出单词w的正确原型,那么P(c|w)就是指,对于给定的单词w,单词c就是w的正确原型的概率,这里利用贝叶斯做定理做一下变型,就可以得到
P(c|w)=P(c*w)/P(w)=(P(w|c)*P(c))/P(w)这样的公式,由于P(w)是给定的,因此P(w)=1,所以整个公式就变成了
P(c|w)=P(w|c)*P(c)
这样。至于为什么要进行这样的变换,Peter Norvig给出的解释是“为了分解变化因素”,如果考虑P(c|w)的话,那么,首先这个块头太大了,有很多因素可以影响这个概率,就是说一个单词w可能是漏写了一个字母,或按到了相邻的键,由于我们不可能知道这个单词会被怎么错写,因此只考虑这个的话就非常难以入手。P(w|c)*P(c)就不同了,首先P(c)是指其出现的概率,这当然是c在所有英语单词中出现的概率,这就很容易了,只要进行一下简单的统计就可以了,一般的方法是分析几本小说,建立一个索引,不过个人认为这种并不具有代表性‖因为首先小说所用的词受作者习性影响,再者小说仅代表了文学方面的单词使用概率,没有涉及其它领域。所以要想建立真正的统计库,还得广泛的抽样,当然抽样也有几种不同的方法,我这图个简单了事,就用的前面的方法,其它的也就不多说了。那么P(w|c)就是指给出的纠正单词就是w想真正表达的那个的概率,比如我想写reliable,确写成了realiable,如果算法给出的纠正是realizable,那就没对,如果进行100次随机试验,80次纠正正确,那P(w|c)=0.8,当然,前提是P(c)均一样的情况下,也就是只考虑该因素的前提下。
好了,说了这么多我们这个数学模型了就成型了只要我们选出P(w|c)P(c)最大的一个就可以了。于是
P=max(P(c|w))=max(P(w|c)P(c))
P(c)与max()都简单,剩下的就是P(w|c),其实这就是一个训练的过程了,大家都知道,改得起越多就越知道该单词会被错拼成什么样,比如recept,很多人都认为其正确的是receipt,所以真正的难点在于如何对计算机进行训练,当然,这里可以使用遗传算法、或神经网络什么的来解决,其实这就是数据挖掘,如果想获得更好的效果,把上下文也考虑进来更好。
Peter Norvig当时也没有想到更好的方法。我倒觉得还是用遗传算法更好一些,因为,首先单词容易进行基因编码,再者进化方向很明确,只要判断是不是想要的就可以了,就是说,我们可以重复地进行训练,比如想输入reliable,确写成了realiable,如果算法给出的纠正是realizable,那就没对,便进行淘汰工作,至于遗传算法的另一个因素,优劣性,可以计算其编辑距离,对于wila(正解为will),显然wild要比win有更好的适应性。所以我觉得遗传算法是可行的。不过惭愧,最近由于要准备毕业方面和入职方面的事,并没有将我这个想法实现,不过以后有时间的话,我会试一试的,当然,有兴趣的也可以试一试。
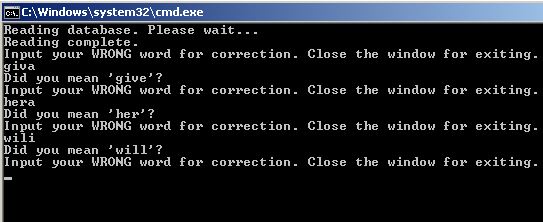
最终效果
评论列表: