Big Table是Google的一种分布式数据库,以:
<row, column, time64> --> value
的映射形式存储数据,现在的主要使用产品为Google Earth, Google Analytics。以下为Big Table的总体部署结构:
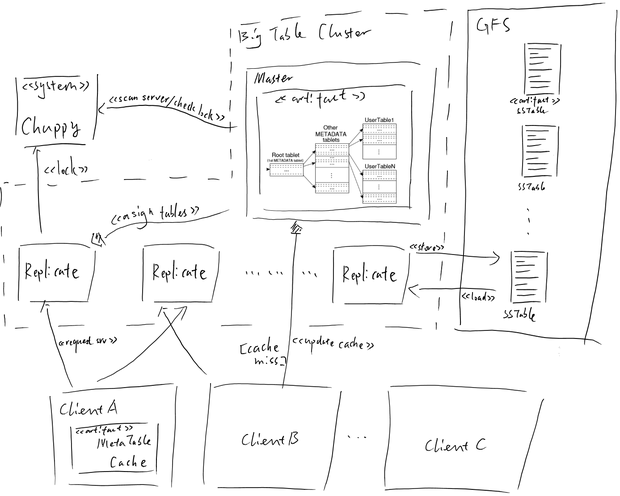
这里面主要有三个系统:Chuppy、BigTable 与 GFS(Google File System),其中GFS(是Google的分布式文件存储)可以与BigTable共用一套Clutster机器。Chuppy这个系统类似于ZooKeeper,是一个Cluter Management应用,提供分布式锁、配置同步、目录等功能,其核心亦是大名顶顶的Paxos。GFS是Google自己的分布式文件系统,提供文件存储、查找服务。
数据结构
BigTable与传统RDB不同的是,其column虽然算是一个维度量,但却是存储在row里的,也就是说column其实是row里的一块数据,这样一来,我们就会看到多个row key相同的row,不过这并不影响映射。由于column是存储在row里的,因此可以非常方便地对column进行扩展(只需要加一个文件块即可),所以其结构也被世人称为“宽表”。
BigTable里的row key即一个简单的64KB大小的字符串,对每个row的读写都是原子的。由于BigTable是基于文件系统存储的,为了提高局部性,BigTable会对row key进行排序。为了简化内容管理,BigTable的权限是依附在column family上的,也就是说权限的管理不是以内容为单位而是以列族为单位的。需要注意的是BigTable本身并不负责生成timestamp,这需要客户端去保证timestamp的唯一性。
BigTable的表索引是以三级B+树的形式存在的,每个结点以METADATA table的形式出现,如下图:
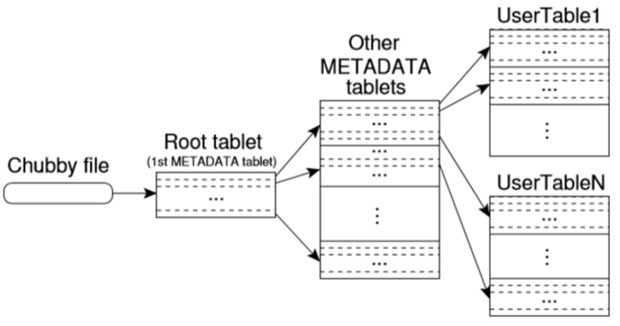
其中的ROOT Table中算是一个特殊的METADATA table,它存储在Chuppy系统中,它存的其它METADATA的地址信息,而这些二级METADATA table才是真正存储table信息的数据结构(注意二级METADATA table都是存储在一起的)。METADATA table每行大概占用1KB内存,每个METADATA table最大为128MB,也就是能存128K=217行,这样三级结构就一共能够索引:217 ∙ 217 = 234 张表,基本上已经足够了。
SSTable作为BigTable的存部存储数据结构,其本质为一系列的数据块,最后为一个索引块(一块的大小一般为64MB),如下图所示。加载SSTable时首先会将索引块加载入内存,之后便可以进行二分查找快速定位数据块。当然也可以直接映射进内存,让操作系统来解决热点问题。
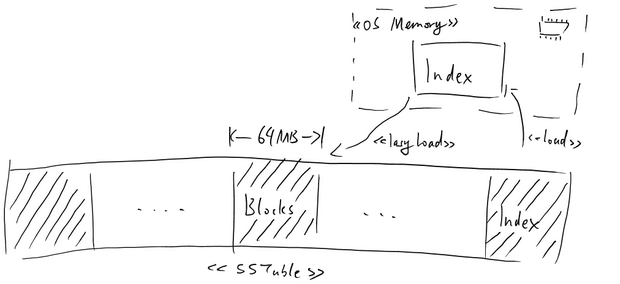
每个Block内部存储的就是最开的所说的是key->value数据。所有的Replicate信息是存储在Chuppy的一个目录中。
分布式原理
当BigTable启动时,会有以下几个步骤:
1. 所有Replicate向Chuppy注册自己(即把自己加入到某个目录下);2. 争先去Chuppy抓取Master文件锁,Chuppy的一致性会保证最终只能有一台Replicate成功,之后其会装载ROOT Table与METADATA Table,这些数据记录着有多少表可以提供数据以及这些表都被分配到了哪一个Replicate;
3. 扫描Replicate注册目录就得到待命的Replicate地址,获得其已经加载的SSTable情况(Master可能换,所以需要这步);
4. 根据METADATA里的信息便可以知道还有哪些SSTable等待分配了。
客户端启动时,首先从Chuppy那个获取Master的地址,然后获取到METADATA信息,便可以路由到正确的Replicate进行数据请求。由于METADATA会被缓存在客户端,所以大多情况客户端都不会与Master通信,实践证明Master的load是非常低的。每级缓存失效都会以递归的形式向上一级查询,所以最差需要6个RTT(Round Trip Time)时间(即ROOT已经不在原来的地址了)。
数据存储、读写
BigTable本身并不存储数据,所有的数据都有以一个名为SSTable的文件结构存储在Google File System(GFS)上。所有的写首先是写在一个全局commit log上(这里可以是块文件映射),这些操作首先会在mem table中会效,待变更积累到一定程度上后便会开始合并(Compact)成一个SSTable文件存储到GFS上,这个过程被称为Minor-Compaction。
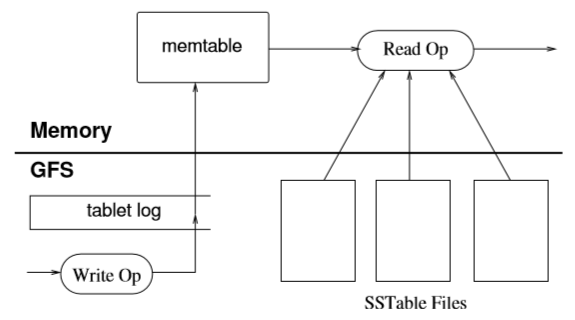
由于Minor-Compaction是增量合并的,之前的SSTable可能包含已经删掉的数据(因为之前的已经持久化了,delete操作只能在当前文件生效),所以当Minor-Compaction达到一定数量后,还需要一个操作把现有的SSTable都合并成一个大的SSTable,被称为Full-Compaction,这个操作会扫描所有的记录,确保删除的数据不会再出现,这里会使用BMDiff与Zippy压缩算法对数据进行压缩。由于数据是散落在多个SSTable之中的,因此查询就不得不遍历所有SSTable,造成性能问题,因此BigTable的设计者在此处添加了Bloom Filter,这种算法能保证否定,但不保证肯定,便很好地的解决了此问题。
容灾/恢复
首先每个Replicate(包括Master)必须定期地向Chuppy刷新自己的文件锁,Master则会定期轮询下属Replicate看其是否健康,如果不能响应其轮询,Master就会尝试抢占Replicate的文件锁,如果抢占成功,Master会就认中该机器出现故障,同时如果此时Replicate发现自己丢失了文件锁,就会进行自杀(Kill itself),Master就会重新分配SSTable至其它Replicate。这里有个问题,就是还有没有持久化成SSTable的commit log该怎么处理,如果全部分配给一个Replicate那显然可能造成负载不均衡的问题,如果分配给多个,那么又可能每个Replicate都需要将commit log全部扫描一遍。为了解决这个问题,BigTable的设计者首先对commit log按“<table,row name,log sequence number>”对其进行排序,这样就减少了离散读(这里的排序可以使用并行排序算法,其开销时间基本上可以忽略不计),然后对其按64MB块大小进行切割并在Master的协调下分配至其它Replicates,便可以高效地加载commmit log。为了降低commit log写失败的概率,BigTable会开两个commit log写进程,正常时候只会开启一个,当写出现问题时就快速切换到另一个,每条commit log的sequence num能保证数据不重复加载。
为了能加快表迁移速度,当Replicate接受到迁移指令后,首先会对已经有commit log进行一次compact操作,完成之后再关闭服务,之后再进行一次compact操作,把剩下的commit log都处理完毕,这样commit log一点都不用读了,当然这个的前提是当前Replicate还能工作,如果是突然当机那还是得用上面的方法。
参考资料(References)
- http://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
- http://blog.csdn.net/opennaive/article/details/7532589
- http://en.wikipedia.org/wiki/BigTable
评论列表: