去年准备申请的一个专利,结果说算法不能申请专利,悲惨(不过另一个同步的过了,也算抵消了),就索性公开出来了~
1、要解决的技术问题是什么?
通过压缩大量离散的字符串数据以提高传输效率。这些数据的特点是,相互隔离、不相关、有序、仅包含ASCII码常见字符(不超过127个),数据量微小(不超过100字节)。
2、详细介绍技术背景,并描述已有的与本发明最相近似的实现方案
ASCII
常见英文与特殊字符在计算内存储时使用的是ASCII(全称 American Standard Code for Information Interchange)码表,该规范制定于1963年,每个字符对应有一个编号,如下表:
由于一个字节(Byte)含有8位,所以对每个字符使用一个字节表示即可。虽然后期进化出多种码表,如GBK,UTF-8等等,它们对以上的字符码表仍然保持不变。如“Hello”,在内存中占5个字节,内容为: 72,101,108,108,111。所以说,对字符串的压缩就是对以上数字串的压缩。
哈夫曼(Huffman)编码
哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法。其通过统计字符出现的频率,然后将最小的两个组合起来再加入原频率组进行再排方法,自底向下组建出编码树,Huffman是目前已知的最优二进制编码。
近似方案
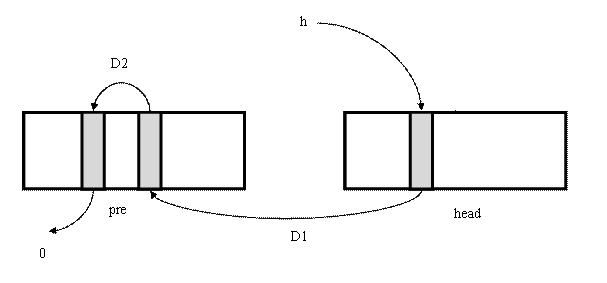
1、 目前常见的压缩算法有:Deflate,LZ系列(LZW,LZMA,LZ77),Bzip2等等,它们都是基于词典的压缩算法。例如Deflate,其一般使用两个32KB的字典(如下图),head与pre,其压缩过程分为二步。首先,从左向右扫描数据,对当前字节进行哈希(Hash)运算,得到一个映射地址(此地址与字节不必一一对应)h。使用该地址到dict字典里查询,如果head[h] != 0,设为D1, 则head[h] 就是上次出现相同字节的位置,之后在两个地方使用线性匹配,得到最长匹配长度C1。之后使用值head[h]到pre里去查询,如果 pre[dict[h]] != 0,设为D2,则匹配长度,得到C2,再使用其值继续在 pre里找,得到C3、C4,直到其 pre取得的值为0。然后取最大的Cmax,这样就找到了离当前字节最近的且匹配长度最大的值Cmax,将字符串替换为{Dn,Cmax}即可,从而达到压缩的目的,例如“abcdfgabc”会被压缩成“abcdfg{6,3}”。最后再使用Huffman进行编码压缩即可。但问题是此类压缩方法均需要存入字典才能进行角压缩,在数据量比较小的时候往往得到的结果比原有的数据长度还要长。
![]()
2、 Simple-9 不使用词典,算法采用的是分组处理方式。其把输入的串以n个bytes(一般是4个)分成一组,然后写入第一个异常数的地址(0~3,即00到11占2 bits)与适合于该n个bytes的最小模m(即2^m > max(B[0],B[1],…,B[n],m一般有4种),如果遇到异常数,则放到数据区后进行处理,同时原地址存下一个异常数的距离。这种算法的问题在于,不能很好的结果数据的自身特点,如局部性,且其不使用词典,因此压缩效果有限。
3、以因果关系推理的方式推导出现有技术的缺点是什么?针对这些缺点,说明本发明的目的及能够达到的技术效果。(现有技术的缺点是针对于本发明的优点来说的,本发明不能解决的缺点不必写)
本发明在传输数据时不用放入字典,因此针对微量数据有很好的压缩效果。
4、本发明技术方案的详细阐述,应该结合流程图、原理框图、电路图、系统结构图进行说明(发明中每一功能的实现都要有相应的技术实现方案;所有附图都应该有详细的文字描述;方法专利都应该提供流程图,并提供相关的系统装置。5.1 本部分为专利申请最重要部分,需要详细提供;5.2 发明必须是一个技术方案,不能只有原理,也不能只做功能介绍;5.3 对于软件、业务方法,要提供流程图;5.4 必须结合流程图、原理框图、电路图、系统结构图等附图进行说明。)
本方案针对微量数据,使用静态字典,即字典不用放入传输数据中,从而避免了现有压缩方法的弊端。本发明分为“压缩”与“解压缩”两部分。
压缩部分
这个部分可以分成4步:字典构造,最近使用转换,分组与值写入。下面分别对每部进行详细说明。
字典构造
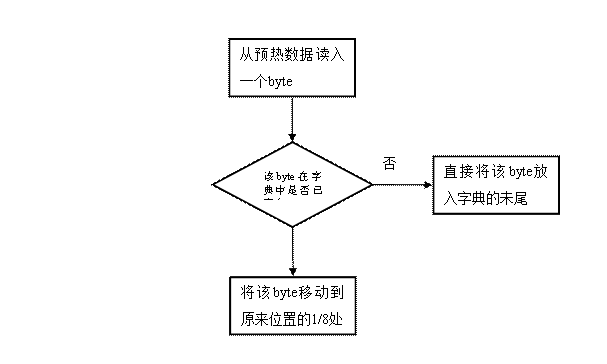
原有的ASCII码表所有字符的位置都是固定的,这样不利于输出较小的数字序列。首先初始化一个空的链表字典,然后读入大量(10MB以上)可能传输的数据。如果读入字符在字典中不存在,则直接加入字典,否则将则字符移动到原有位置的[1/8]处,经过大量数据的预处理后,字典就会变得适用当前环境下的数据。(这里的适应指的是字符的编号合能达到较小的值。)然后将该字典分发到发送方与接收方。
最近使用转换
字典构造从整体上适应了数据,但对于当前串,仍然可能输出较大的序列。这里根据最近使用的byte对字典再作一次临时变化。当从输入串中输入一个byte时,首先输出该byte的下标,将该byte移动到原位置的 [1/8] 处,这样如果下次再出现同样的byte,就能输出较小的序列了。
例如:当输入 aabbcc,字典为cba时
扫描位置 输出 字典
1 3 acb
2 3,1 abc
3 3,1,2 bca
4 3,1,2,1 bca
5 3,1,2,1,2 cba
6 3,1,2,1,2,1 cba
若不使用该变化,输出为:3+3+2+2+1+1=12,变化之后为 3+1+2+1+1=8,而且具有较好的局部性。
编码、分组与数据写入
首先定义一下本发明使用的数据结构:对于每个byte,定义一种模式m,可选的模式为{3,4,7},使用2bits来存储,即{00=3,01=4,1=7}。模式m要求满足“2^m > byte在字典中的下标 ”,这里的m 其实就代表了压缩后的byte数据长度。如果m=3,4,则需要使用1bit来存储“组团位”,“组团位”如果为1,则表示下一个数据仍然使用m模式,如果m=7就不用1bit来组团了,原因一是m=7这种情况不会太高,二是即便组团,若为2个数据,组团模式m占1bits,两个组团位占2bits,两数据占2*7=14bits,即总共为17bits;若不组两个m占2bits,两个数据 2*7=14bits,总共为16bits。因此在m=7时不组要合算些。若当前字符为最后一个,则不用写入组团位。当扫描结束后,如果有字节没有填满,应全额补0。例如: 10,1,60,3 编码后如下:
 其中“红色”代表模式位,“绿色”代表组团位, “蓝色”代表数据位而“黑色”代表没有使用的位。可以看到。本发明将原有的4个byte压缩成了3个,压缩率75%。
其中“红色”代表模式位,“绿色”代表组团位, “蓝色”代表数据位而“黑色”代表没有使用的位。可以看到。本发明将原有的4个byte压缩成了3个,压缩率75%。
这里有个问题,如果如何选择最有效的分组,以使得总的bits长度能最小,例如:
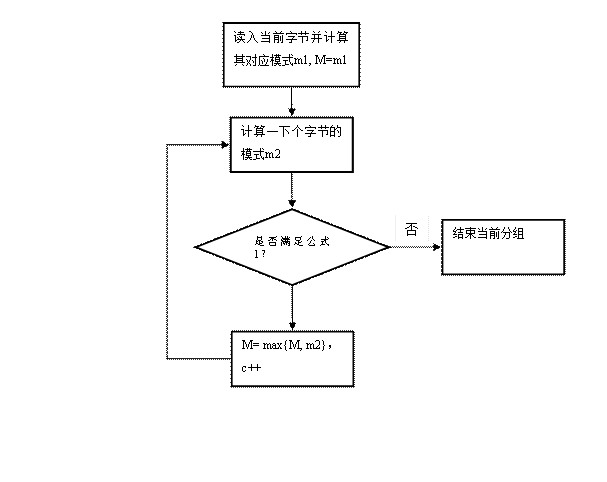
10,1,3,13 可以分组成 [10], [1,13], [3] 需要 2+5+2+4+4+2+4=23bits,也可以分成[10,1,13,3],这时m=4,需要2+5*4=22bits。后一种显然是理想情况,需要提前对整个输入串进行分析,称之为OPT算法。在本发明中,使用“最大匹配算法”,即在当前m值的情况下,尽可以能多的把数据纳入到当前分组来。设当前字符对应的模式m为m1,M=max{M,m2},M初始为第一个分组的第一个byte的模式,下一个字符为m2,已纳入分组的字符数量为c,则仅当满足
公式1:
![]()
才将下一个字符纳入到该组中。当然,这时所有的操作都要保证在输入串范围之内(即c < seq.length,其中seq是输入的串),否则会出现越界,此外为了方便说明,故特意简化之。流程图如下:
最后,按照分好的组与前面定下的数据结构写入数据即可。
解压缩部分
首先需要根据上面定义的数据结构,解压出变换后的编码。而前面对字典使用的“最近使用转换”显然是可逆的,所以按照之前的约定操作即可复原数据。例如,根据数据数据结构解压出来的序列是:3,1,2,1,2,1 字典 cba,则:
步骤 数据 字典
1 a,1,2,1,2,1 cba
2 a,a,2,1,2,1 acb
3 a,a,c,1,2,1 cab
4 a,a,c,c,2,1 cba
5 a,a,c,c,b,1 bca
6 a,a,c,c,b,b bca
这样就完成了数据的解压缩。
5、能实现本发明目的的其他替代方案
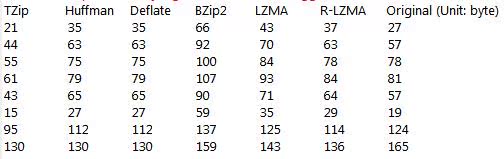
目前来说有deflate、LZMA、Bzip2与simple-9算法,试验显示,本发明能在150 Bytes数据内取得比它们都要好的效果。(下表 TZip 即代表本发明)
评论列表: